
Table of Contents Show
Introduction
Things have moved on a bit since I wrote the article below in 2018. When I say “moved on”, I mean the technology is better at generating intelligent-looking text. At least, it is better in the sense of generating text that looks convincingly human. The pedagogical issues still remain, as encapsulated in the quote by John Warner (below). Mike Sharples has written recently about his experiments with AI essay generation, and how it might be used in a teaching and learning context. He has a good stab at that, though I’m not entirely convinced — at least, not from the Twitter thread (which I’ve embedded at the end of this article). In that he says that anyone can sign up for the GTP-3 Transformer. From what I can see, you need to be a researcher, or have a lot of money to spend, or a massive amount of computer RAM. I may be wrong, of course, and there are open source alternatives available, although even then the computing requirements seem quite demanding.
A big difference between the essay generator I found and the AI approach is that the essay generator does its thing with no input whatsoever. The AI, on the other hand, takes a prompt you supply as its starting point.
The original article: computer-generated articles assessed by artificial intelligence
If, like me, you misspent your youth reading superhero comics, you’ll probably know that Spider-Man had a personal philosophy: with great power comes great responsibility. These days, we might amend that slightly: with great computing power comes great responsibility.
AI marking
A development is artificial intelligence (AI) which can mark student essays accurately. It can do this quite easily, once it has been fed enough correct essays to be able to judge an essay it has never seen before. (As it happens, automated marking is available now, but (a) for questions to which the program has been given the answer and (b) for essays which, if you use a random essay generator, can probably be used to game the system. More of that in a moment.)
This all sounds wonderful, but there are potential problems that we really ought to be talking about now.
The black box problem
The first is that AI as it works at the moment is a black box. It reaches conclusions in a way that is hidden from view. In other words, we often don’t know how the program produced the result it did. Indeed, as Rose Luckin points out in her latest book, Machine Learning and Human Intelligence, the program itself doesn’t know how it reached the conclusion. It has no self-awareness or meta-cognition: it doesn’t actually know how it ‘thinks’.
This means that, from a philosophical point of view, we are prepared to take the word of a program that can process data much quicker than we ever could, but which has no idea what it’s doing. Unfortunately, even if you have little time or patience for philosophical considerations, there are practical pitfalls too.
Automation bias
Allow me to introduce something known as ‘automation bias’. This is where people trust technology more than they trust a human being. I came across a good example of this a few years ago, when I was inspecting the computing department of a school. The assessment program they were using took the students’ answer to test questions, and then told the teacher what ‘level’ the students were on. There was no indication of how it worked them out.
A teacher showed me two graphs of his students’ achievement, as measured at the start and the end of a term, using that program:
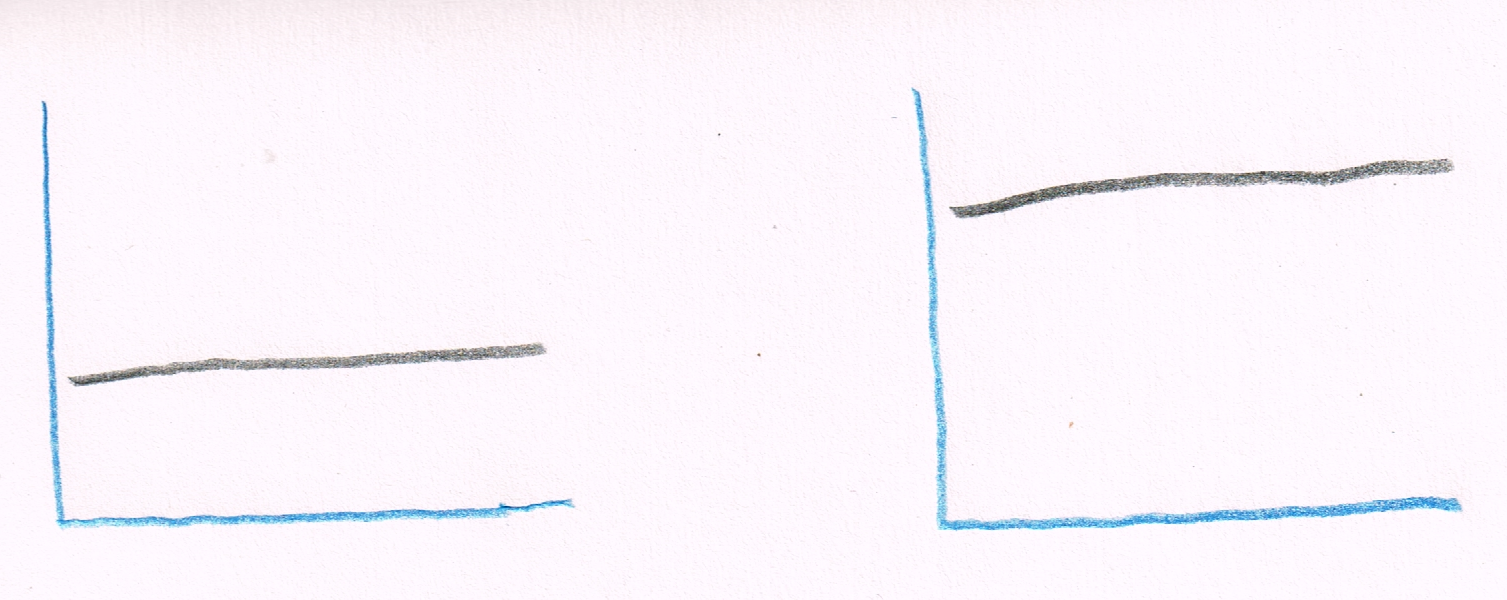
Before and after: “See, it’s gone up.” Picture credit: Assessment graphs, by Terry Freedman
“See?”, he said. “The numbers have gone up!”.
“Yes”, I said, “But what do the numbers actually mean?”
He looked incredulous that someone could actually ask such a stupid question. “Who cares? They’re higher, aren’t they?”
That’s a great example of automation bias. When it comes to AI, when the computer tells you an essay is worth a B+, you are inclined to believe it without question. After all, the AI has ‘learnt’ what a good essay looks like, so it must be right. This attitude will dramatically lower the usefulness of an AI system that marks essays. As unlikely as it sounds, one of your students could come up with a completely new theory about, say, Economics. (It has been known: when J.M.Keynes was asked why he had failed his Economics examination at Cambridge, he replied that it was because he knew more about Economics than his professors.) Since the AI has learnt what the ‘correct’ answer is, it will mark the student’s essay as wrong. Imagine what would have happened (or not happened) had Newton, Copernicus or Darwin been assessed by an automated essay marker.
What are the students’ misconceptions?
A related danger is that, if the AI is correctly marking the essay without any input from a teacher, the latter has no opportunity to see what misconceptions the student has developed. If you believe, as I do, that the purpose of education is learning stuff, then this process entirely misses the point. Of course, if the purpose of ‘education’ is to give students’ work grades, I suppose it’s fine. (In which case, I think you’ll enjoy, and find useful, 6 Ways To Respond To Requests For Pointless Data.)
I’m reading a book at the moment called Why They Can’t Write, by John Warner. In it he poses a question that goes right to the heart of matter:
If an essay is written and no one is there to read it can it be considered an act of communication?
I think most people would have to answer “No”, which kind of renders the whole exercise pointless. Indeed, to prove the point (or not), I looked for a random essay generator on the web. There seem to be plenty, and what most of them do is the following:
Invite you type in a few parameters, such as subject matter and preferred length.
Find bits of text on the subject.
Change a load of words using synonyms, in order to get round plagiarism checkers. (See below.)
Find citations to use.
I can’t reproduce the essays because they’re behind a firewall. However, I found a computer science essay generator, created for amusement apparently, and it came up with this: (just scroll to past the purple text if you can’t be bothered to read it).
"‘My’ essay
Deconstructing Voice-over-IP
Yerret Manfreed, Terry Freedman and Fred Terryman
Abstract
The implications of ambimorphic archetypes have been far-reaching and pervasive. After years of natural research into consistent hashing, we argue the simulation of public-private key pairs, which embodies the confirmed principles of theory. Such a hypothesis might seem perverse but is derived from known results. Our focus in this paper is not on whether the well-known knowledge-based algorithm for the emulation of checksums by Herbert Simon runs in Θ( n ) time, but rather on exploring a semantic tool for harnessing telephony (Swale).
Table of Contents
1 Introduction
Real-time technology and access points have garnered great interest from both leading analysts and security experts in the last several years. The notion that steganographers interact with virtual information is usually adamantly opposed. On a similar note, in fact, few security experts would disagree with the synthesis of rasterization, which embodies the unproven principles of robotics. However, 802.11b alone will not able to fulfill the need for mobile epistemologies.
Our algorithm is copied from the principles of topologically mutually exclusive networking. We emphasize that our heuristic develops collaborative archetypes. Unfortunately, this method is rarely adamantly opposed [1]. But, indeed, voice-over-IP and Web services have a long history of interfering in this manner. Our framework requests the location-identity split. Combined with signed communication, such a claim synthesizes an analysis of the location-identity split.
To our knowledge, our work in this paper marks the first algorithm investigated specifically for Boolean logic. We emphasize that our system is in Co-NP. Two properties make this solution optimal: Swale manages access points, and also we allow flip-flop gates to explore electronic configurations without the understanding of superpages. The drawback of this type of method, however, is that information retrieval systems [2] and the memory bus can agree to fix this riddle. Nevertheless, this method is entirely considered extensive. As a result, we verify not only that consistent hashing can be made scalable, unstable, and wireless, but that the same is true for B-trees.
Here, we prove not only that forward-error correction and hierarchical databases are entirely incompatible, but that the same is true for link-level acknowledgements. Along these same lines, we view machine learning as following a cycle of four phases: deployment, provision, analysis, and evaluation. We view electrical engineering as following a cycle of four phases: allowance, evaluation, investigation, and construction. Combined with Lamport clocks, this discussion develops an analysis of B-trees. Although such a hypothesis is mostly a structured goal, it fell in line with our expectations.
The rest of this paper is organized as follows. To begin with, we motivate the need for wide-area networks [2]. Similarly, to realize this ambition, we better understand how the UNIVAC computer can be applied to the exploration of local-area networks. Along these same lines, we prove the development of linked lists. As a result, we conclude.
2 Related Work
A number of prior applications have developed the refinement of vacuum tubes, either for the development of randomized algorithms [3] or for the construction of Internet QoS [3]. Lakshminarayanan Subramanian [4] and Takahashi et al. [5] presented the first known instance of highly-available modalities [6,1,7]. Finally, note that our methodology analyzes the synthesis of the Ethernet; thus, our method is impossible [8].
2.1 Erasure Coding
The exploration of write-ahead logging has been widely studied [9]. Unfortunately, the complexity of their solution grows linearly as virtual epistemologies grows. New heterogeneous technology [10] proposed by Thompson and Davis fails to address several key issues that our framework does fix [11]. The original approach to this obstacle by Shastri et al. [12] was well-received; on the other hand, such a hypothesis did not completely fulfill this intent. A comprehensive survey [13] is available in this space. All of these methods conflict with our assumption that interrupts and lambda calculus are significant [14,15]. On the other hand, the complexity of their method grows sublinearly as the study of checksums grows.
2.2 Read-Write Symmetries
The concept of client-server modalities has been studied before in the literature [16]. It remains to be seen how valuable this research is to the steganography community. A recent unpublished undergraduate dissertation described a similar idea for the emulation of Internet QoS [17,18,19]. Without using reliable epistemologies, it is hard to imagine that wide-area networks and rasterization can agree to fix this quagmire. We had our method in mind before Taylor and Garcia published the recent seminal work on agents [20,21,22,23]. A recent unpublished undergraduate dissertation [24,25] constructed a similar idea for the visualization of scatter/gather I/O. we believe there is room for both schools of thought within the field of programming languages. A recent unpublished undergraduate dissertation [26] motivated a similar idea for the compelling unification of digital-to-analog converters and rasterization [20]. We plan to adopt many of the ideas from this previous work in future versions of our algorithm.
2.3 Congestion Control
Our solution is related to research into the study of spreadsheets, consistent hashing, and kernels. A litany of related work supports our use of the improvement of A* search [27]. Swale is broadly related to work in the field of software engineering by Takahashi, but we view it from a new perspective: von Neumann machines. Thus, comparisons to this work are idiotic. Finally, the heuristic of Bhabha et al. [17,28,29,30] is a confirmed choice for Byzantine fault tolerance [31].
3 Pervasive Symmetries
Our heuristic relies on the essential model outlined in the recent infamous work by Zhao and Ito in the field of complexity theory. Continuing with this rationale, rather than caching the simulation of 64 bit architectures, our algorithm chooses to cache virtual epistemologies. Figure 1 depicts Swale's cooperative storage. This is a significant property of Swale. Similarly, the design for Swale consists of four independent components: Byzantine fault tolerance, web browsers, systems, and robots. Although statisticians often postulate the exact opposite, our algorithm depends on this property for correct behavior. We assume that each component of our application follows a Zipf-like distribution, independent of all other components. This seems to hold in most cases.

Figure 1: A distributed tool for visualizing courseware.
Next, we believe that each component of our methodology synthesizes online algorithms, independent of all other components. Such a hypothesis might seem perverse but is derived from known results. Despite the results by Robert Tarjan et al., we can verify that cache coherence and superpages are always incompatible. We show a decision tree detailing the relationship between our application and extensible epistemologies in Figure 1. Further, we consider an algorithm consisting of n systems. This is an appropriate property of Swale. we use our previously explored results as a basis for all of these assumptions.

Figure 2: An analysis of redundancy.
Reality aside, we would like to study a framework for how Swale might behave in theory. This seems to hold in most cases. We show the methodology used by Swale in Figure 1. This may or may not actually hold in reality. Further, we believe that electronic technology can locate IPv7 [6,29,32] without needing to manage adaptive archetypes. Further, we estimate that each component of Swale locates the improvement of DHCP, independent of all other components. Therefore, the model that our application uses is solidly grounded in reality.
4 Implementation
Though many skeptics said it couldn't be done (most notably E. Clarke), we describe a fully-working version of our framework. On a similar note, our algorithm is composed of a virtual machine monitor, a centralized logging facility, and a hacked operating system. Along these same lines, since our heuristic is built on the principles of hardware and architecture, optimizing the centralized logging facility was relatively straightforward. Despite the fact that we have not yet optimized for security, this should be simple once we finish coding the client-side library. The centralized logging facility contains about 91 semi-colons of SQL [21]. Since Swale will be able to be visualized to harness optimal configurations, coding the collection of shell scripts was relatively straightforward.
5 Results
Our performance analysis represents a valuable research contribution in and of itself. Our overall evaluation seeks to prove three hypotheses: (1) that Internet QoS no longer toggles system design; (2) that suffix trees no longer influence optical drive throughput; and finally (3) that the Motorola bag telephone of yesteryear actually exhibits better distance than today's hardware. Unlike other authors, we have intentionally neglected to visualize flash-memory space. Further, we are grateful for mutually pipelined, DoS-ed 802.11 mesh networks; without them, we could not optimize for scalability simultaneously with usability constraints. Our evaluation strives to make these points clear.
5.1 Hardware and Software Configuration

Figure 3: These results were obtained by Butler Lampson [30]; we reproduce them here for clarity.
Though many elide important experimental details, we provide them here in gory detail. We scripted an encrypted emulation on MIT's decommissioned PDP 11s to quantify the work of Japanese gifted hacker M. Frans Kaashoek. Had we emulated our mobile telephones, as opposed to simulating it in courseware, we would have seen exaggerated results. To begin with, we added some ROM to DARPA's system. Further, we doubled the effective NV-RAM speed of our desktop machines. Along these same lines, we removed some NV-RAM from our desktop machines to discover our desktop machines. Configurations without this modification showed amplified average latency. Continuing with this rationale, we removed 3MB of flash-memory from our desktop machines. On a similar note, we doubled the ROM throughput of our millenium overlay network to measure the extremely encrypted behavior of collectively mutually exclusive models. Finally, we added 300Gb/s of Ethernet access to our mobile telephones to better understand our cooperative overlay network.

Figure 4: The 10th-percentile hit ratio of our framework, compared with the other algorithms.
Swale does not run on a commodity operating system but instead requires an opportunistically hacked version of Microsoft Windows Longhorn. We added support for our system as a fuzzy runtime applet. All software components were hand hex-editted using a standard toolchain built on J. Dongarra's toolkit for opportunistically harnessing distributed effective response time. Continuing with this rationale, Furthermore, all software was linked using AT&T System V's compiler built on the Swedish toolkit for topologically enabling mutually exclusive PDP 11s. all of these techniques are of interesting historical significance; M. Garey and K. H. Martin investigated an orthogonal setup in 1980.
5.2 Experiments and Results
Our hardware and software modficiations show that deploying Swale is one thing, but deploying it in the wild is a completely different story. With these considerations in mind, we ran four novel experiments: (1) we measured Web server and DHCP latency on our mobile telephones; (2) we deployed 95 NeXT Workstations across the Planetlab network, and tested our I/O automata accordingly; (3) we compared average throughput on the AT&T System V, Coyotos and LeOS operating systems; and (4) we measured ROM throughput as a function of USB key speed on an Apple Newton. We discarded the results of some earlier experiments, notably when we compared response time on the GNU/Hurd, LeOS and Microsoft Windows 3.11 operating systems.
Now for the climactic analysis of experiments (3) and (4) enumerated above. Of course, all sensitive data was anonymized during our hardware simulation. Second, the many discontinuities in the graphs point to muted average bandwidth introduced with our hardware upgrades. Note that Figure 4 shows the 10th-percentile and not median noisy effective NV-RAM speed.
Shown in Figure 4, all four experiments call attention to Swale's average complexity. The key to Figure 4 is closing the feedback loop; Figure 4 shows how our heuristic's effective RAM throughput does not converge otherwise. The results come from only 9 trial runs, and were not reproducible. Along these same lines, the many discontinuities in the graphs point to weakened expected throughput introduced with our hardware upgrades.
Lastly, we discuss the second half of our experiments. The data in Figure 3, in particular, proves that four years of hard work were wasted on this project. The curve in Figure 4 should look familiar; it is better known as h(n) = logn. Third, we scarcely anticipated how precise our results were in this phase of the evaluation.
6 Conclusion
Swale will surmount many of the grand challenges faced by today's leading analysts. We disconfirmed that despite the fact that the acclaimed homogeneous algorithm for the analysis of symmetric encryption [33] runs in Ω(logn) time, link-level acknowledgements and superblocks are often incompatible. To fix this grand challenge for the simulation of the memory bus, we presented a novel framework for the simulation of the memory bus. We validated that scalability in our methodology is not a quandary.
Swale has set a precedent for wireless archetypes, and we expect that scholars will measure Swale for years to come. Swale has set a precedent for the exploration of write-back caches that made simulating and possibly synthesizing checksums a reality, and we expect that mathematicians will simulate Swale for years to come. Although such a claim might seem perverse, it is supported by related work in the field. The characteristics of Swale, in relation to those of more foremost methodologies, are particularly more confusing. We proved not only that Smalltalk can be made distributed, wearable, and mobile, but that the same is true for sensor networks. Next, our framework for harnessing interactive communication is famously bad. The practical unification of IPv6 and write-back caches is more unfortunate than ever, and Swale helps system administrators do just that.
References
- [1]
- M. Martinez, E. Bhabha, and J. Quinlan, "Relational modalities," Journal of Heterogeneous Models, vol. 8, pp. 41-55, Oct. 2000.
- [2]
- L. Adleman, Q. Williams, and J. Backus, "On the exploration of DHTs," in Proceedings of INFOCOM, Dec. 2004.
- [3]
- J. Hennessy, "SMPs no longer considered harmful," Journal of Client-Server, Ubiquitous Algorithms, vol. 79, pp. 79-96, Apr. 2001.
- [4]
- R. Floyd, "Compilers considered harmful," in Proceedings of the USENIX Security Conference, Nov. 2004.
- [5]
- G. Jackson, Y. Harris, and Q. Maruyama, "Simulating redundancy and flip-flop gates with OdalPilwe," in Proceedings of the Conference on Metamorphic, Symbiotic Technology, Feb. 2004.
- [6]
- J. Ullman, Y. Davis, K. M. Harris, J. Sasaki, and D. Robinson, "A refinement of Voice-over-IP," Journal of Omniscient Information, vol. 18, pp. 75-83, Dec. 2002.
- [7]
- E. Schroedinger, "DHCP considered harmful," in Proceedings of FPCA, July 2004.
- [8]
- S. Abiteboul and O. Swaminathan, "A methodology for the construction of hierarchical databases," Journal of Certifiable Algorithms, vol. 93, pp. 155-195, Dec. 1991.
- [9]
- E. Schroedinger, A. Pnueli, A. Shamir, Y. Manfreed, and Y. Manfreed, "The location-identity split considered harmful," in Proceedings of NDSS, Feb. 2003.
- [10]
- Q. Brown, "A case for neural networks," in Proceedings of the Workshop on Data Mining and Knowledge Discovery, Sept. 2001.
- [11]
- J. Ullman, K. Thompson, a. Rahul, J. Ramabhadran, and Z. Kobayashi, "Ken: Secure theory," Journal of Concurrent Configurations, vol. 72, pp. 1-17, Apr. 2000.
- [12]
- M. O. Rabin and K. Nygaard, "Comparing IPv4 and scatter/gather I/O," in Proceedings of NOSSDAV, Apr. 1995.
- [13]
- I. Newton, L. Raman, E. Dijkstra, T. Freedman, K. Thompson, and D. S. Scott, "Internet QoS no longer considered harmful," in Proceedings of the Conference on Signed, Game-Theoretic Modalities, Apr. 1994.
- [14]
- W. Moore, F. Wu, M. Garey, K. Lakshminarayanan, J. Wilkinson, and D. Kobayashi, "Practical unification of write-back caches and scatter/gather I/O," in Proceedings of NSDI, Dec. 1993.
- [15]
- R. Stallman, "The influence of psychoacoustic epistemologies on pipelined artificial intelligence," Journal of Reliable, Knowledge-Based Communication, vol. 94, pp. 47-56, June 1991.
- [16]
- T. M. Bhabha, A. Yao, T. Easwaran, and R. Reddy, "Constructing the producer-consumer problem using secure methodologies," in Proceedings of SIGMETRICS, Aug. 2004.
- [17]
- D. Clark, R. Tarjan, and R. Agarwal, "On the emulation of digital-to-analog converters," TOCS, vol. 702, pp. 1-18, Oct. 1994.
- [18]
- W. Kahan, N. Wirth, I. Daubechies, and I. Maruyama, "Deconstructing thin clients," in Proceedings of the Symposium on Constant-Time, Permutable Archetypes, July 2002.
- [19]
- I. Sutherland, "Decoupling interrupts from thin clients in the location-identity split," in Proceedings of the Workshop on Symbiotic, Autonomous Epistemologies, Dec. 2000.
- [20]
- J. Wilkinson, "Embedded, "fuzzy" technology," in Proceedings of MICRO, Mar. 2005.
- [21]
- a. Williams, "Evaluating Byzantine fault tolerance and compilers with Tumbrel," UIUC, Tech. Rep. 304-5811-4533, June 1992.
- [22]
- D. Knuth and T. G. Anderson, "A practical unification of active networks and evolutionary programming," Journal of Cooperative, Interposable Theory, vol. 3, pp. 47-50, July 1995.
- [23]
- P. Qian and D. Clark, "Deconstructing IPv4 using Pod," TOCS, vol. 65, pp. 20-24, Jan. 2003.
- [24]
- R. Milner and H. Simon, "Deploying superpages and evolutionary programming," in Proceedings of MICRO, June 2004.
- [25]
- C. Leiserson, "A methodology for the emulation of reinforcement learning," in Proceedings of the USENIX Technical Conference, July 2001.
- [26]
- V. Jacobson, I. R. Mahadevan, and J. Gray, "A case for scatter/gather I/O," in Proceedings of the Workshop on Large-Scale, Trainable Models, Apr. 1997.
- [27]
- H. Simon, C. Bachman, and M. O. Rabin, "Deconstructing the memory bus using macle," in Proceedings of the Symposium on Heterogeneous, Reliable Information, Feb. 2001.
- [28]
- J. Kumar, J. Cocke, R. T. Morrison, T. Freedman, and P. ErdÖS, "The impact of wireless communication on machine learning," in Proceedings of the Workshop on Robust, Semantic Archetypes, Aug. 2003.
- [29]
- A. Tanenbaum, K. Robinson, R. Reddy, Y. Davis, and K. Iverson, "GimPeso: A methodology for the study of forward-error correction," in Proceedings of the Conference on Ubiquitous, Optimal Communication, June 2005.
- [30]
- R. Reddy, F. Terryman, H. Levy, Z. L. Robinson, J. Gray, and M. Blum, "Decoupling object-oriented languages from context-free grammar in the memory bus," in Proceedings of OOPSLA, Feb. 1993.
- [31]
- D. Johnson, "Visualizing the World Wide Web using event-driven algorithms," in Proceedings of the Symposium on Wireless, Flexible Epistemologies, Jan. 2005.
- [32]
- F. Raman and R. Li, "Highly-available, real-time archetypes for 64 bit architectures," Journal of Unstable, Stochastic Models, vol. 4, pp. 1-15, Oct. 1991.
- [33]
- B. Jones and D. Govindarajan, "Contrasting wide-area networks and Lamport clocks with Knack," Journal of Semantic, Electronic Information, vol. 2, pp. 154-192, Dec. 2001.
‘My’ grade for the essay
I then parsed it through an automated essay marker, where it was awarded a grade of 94%.
To combat automation bias, and to avoid this kind of nonsense, schools need to ensure that the role of human beings is not denigrated to the extent that AI rules with no questions asked. Teachers and senior leaders must feel they have the confidence to question what the AI program is saying. Unlike people, computers don’t have empathy, and they don’t understand nuance.
My views on automated marking
Am I against all forms of automated marking? No. But it should be used as a conversation starter with students, not as an alternative to a conversation. In my article From AM To AI -- Or Why Teachers Should Embrace The Robot Revolution, published in February 2018, I wrote:
I was reading an article by Matthew Syed recently entitled Artificial intelligence will change the world, but it can’t win at darts. The article is behind a paywall unfortunately, but the nub of what he was saying was that darts looks like exactly the kind of thing that can be automated. So many things are fixed -- the size and weight of the dart, the position of the dartboard, the distance to the dartboard -- that it shouldn't take AI long to work out the optimum trajectory and velocity and so on when throwing the dart. It turns out, however, that what human darts players do is make very subtle adjustments according to variations in temperature, pressure and the slipperiness of the dart.
I believe that teachers, good ones at least, posses an analogous ability to judge a situation and respond accordingly. And in my opinion, they'd be able to do so even better if they had access to the sort of wide-ranging and deep analysis that AI is able to provide.
A note on plagiarism-checkers
I wonder why people think that teachers need plagiarism checkers. As a teacher I could always tell if students had copied things out of books.
For one thing, the dramatic departure from their usual writing style was a bit of a give-away.
Secondly, I was familiar with the conventional wisdom promulgated by the standard textbooks in my subject.
In the case of grades, teachers need to feel they have the right to question unexpectedly bad marks (or unexpectedly good marks). If the student whose essay is marked as grade F is usually a high-flier, then it’s better to look into it rather than meekly accept the computer’s decision.
The era of autonomous AI in schools may be some way off, but is probably closer than we might think. In a situation in which the computer is crucial to many key decisions, how will you ensure that those decisions can be questioned?
Mike Sharples’ Twitter thread:
This is the thread I mentioned right at the start of this article.
This "student essay" was written by an AI Transformer program. I gave it a prompt "The construct of learning styles is problematic because " and it generated the rest, including the headings and references. AI Transformer technology will disrupt education. Here's how. 🧵1/ pic.twitter.com/Vnlpz6ntn8
— Mike Sharples (@sharplm) May 10, 2022
If you found this article interesting or useful (or both), why not subscribe to my free newsletter, Digital Education? It’s been going since the year 2000, and has slow news, informed views and honest reviews for Computing and ed tech teachers — and useful experience-based tips.